Microsoft speichert Daten in DNA
Archivmeldung vom 04.06.2021
Bitte beachten Sie, dass die Meldung den Stand der Dinge zum Zeitpunkt ihrer Veröffentlichung am 04.06.2021 wiedergibt. Eventuelle in der Zwischenzeit veränderte Sachverhalte bleiben daher unberücksichtigt.
Freigeschaltet durch Sanjo Babić
Derzeit vollzieht sich weitgehend unbemerkt eine Entwicklung auf der Schnittstelle zwischen Informationswissenschaft und Biotechnologie. Einer der Hauptplayer ist Microsoft. Es geht darum, DNA, synthetisch hergestellte DNA, als Speicher für Informationen zu benutzen. Dies berichtet das Magazin "Unser Mitteleuropa" unter Verweis auf Berichte in "ScienceFiles" und "FreeThink.com".
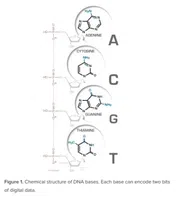
Weiter berichtet das Magazin: "DNA besteht aus Nukleotiden oder Basen, aus vier Basen: Adenine, Cytosine, Guanine und Thymine (A, C, G oder T). Speichermedien, die derzeit im Handel sind, arbeiten auf Basis von binären Codes, kennen also nur die Werte 1 und 0. Die Idee, DNA als Speichermedium zu nutzen, setzt somit ein neues Coding voraus: 00 -> A; 01 -> C, 10 -> G und 11 -> T.
Jede Zelle im menschlichen Körper enthält ein menschliches Genom. Ein menschliches Genom besteht aus ca. 6 Milliarden Basenpaaren, die in 23 Chromosomen-Sets organisiert sind. In der DNA dieser Chromosome sind rund 1,6 Gigabytes an Information gespeichert. Jede menschliche Zelle enthält somit 1,6 Gigabyte an Daten. Alle Zellen im menschlichen Körper speichern rund 100 Zettabyte an Daten, mehr Daten als die Menschheit bislang in digitaler Form produziert hat.
Die Idee, DNA als Speicher für Daten zu nutzen, sie hat – wie man sieht – einen gewissen Appeal, denn DNA ist in der Lage, große Mengen von Information auf kleinstem Raum zu speichern, in 3‑D. DNA ist extrem stabil, so dass technische Neuerungen wie der Sprung vom Floppy zur CD und zur DVD und die dabei entstehenden hohen Transformationskosten vermieden werden können, denn DNA kann gespeicherte Information über Jahrhunderte, wenn nicht Jahrtausende konservieren. Die Fortschritte auf dem Feld der Mikrobiologie haben zudem dazu geführt, dass es schnell und billig möglich ist, DNA zu kopieren. Die einzigen Probleme, die sich mit DNA als Speicher und aus technischer Sicht verbinden, sind das Schreiben der Daten in die DNA, das Speichern der Daten, das Auslesen der Daten und das Lesen der Daten.
Alles Probleme, die zwischenzeitlich gelöst sind.
Die Idee, DNA als Speicher für Daten zu benutzen, ist bereit Ende der 1980er Jahre aufgekommen, Ende der 1990er Jahre war es bereits gelungen, Daten in DNA zu speichern. Fortschritte bei der Sequenzierung und der Synthese von DNA haben schließlich dazu geführt, dass DNA als Speichermedium erforscht und zu mittlerweile erstaunlicher Virtuosität entwickelt wurde. Von den 28 Basenpaaren, in denen Joe Davis im Jahre 1988 erfolgreich Information abgelegt hat (das Projekt trug den Namen “Microvenus”, für diejenigen, die es nachlesen wollen), hat sich die Forschung in geradezu Windeseile weiterentwickelt. 2016 gelang es Microsoft in Zusammenarbeit mit Luis Ceze und Karin Strauss von der University of Washington und in Zusammenarbeit mit Twist Bioscience, einem der wichtigsten Player im Feld, rund 1 Gigabyte an Daten aus Musik-Videos, Büchern aus dem Projekt Guttenberg und vieles mehr zu speichern und auszulesen. 2019 gelang es die komplette Wikipedia in DNA zu übertragen, und seit 2019 ist es Twist Bioscience möglich, lange Oligonukleotide zu synthetisieren und als Speichermedium zu nutzen.
Dabei wird im Wesentlichen eine Phosphoramidit-Synthese durchgeführt, die Nukleinsäuren erzeugt. Das Verfahren ist der Polymerase Kettenereaktion, bei der ein Ausgangsstück DNA genutzt und verfielfältigt wird, insofern überlegen, als auf das Ausgangsstück DNA verzichtet werden kann. Statt dessen wird Silizium als Substrat genutzt, um DNA synthetisch zu erzeugen: „Twist Bioscience hat eine neuartige Plattform für die Herstellung synthetischer DNA in einem massiv parallelen Maßstab entwickelt. Anstatt DNA auf festen Substraten der vorherigen Generation wie Plastik- oder Glasperlenreaktoren zu synthetisieren, verwendet die Technologie von Twist kundenspezifisch gefertigte Siliziumwafer und synthetisiert Millionen einzigartiger Oligonukleotidsequenzen in jedem Syntheselauf, mit verbesserten Synthesefehlerraten und Sequenzgleichförmigkeit gegenüber früheren Methoden. Zukünftige Generationen der DNA-Synthese-Technologie werden derzeit speziell für die DNA-basierten digitalen Speicheranwendungen entwickelt, um DNA in einem noch höheren Durchsatzmaßstab zu produzieren.“
Die Technik, um Information in DNA zu speichern, sie ist vorhanden. Fortschritte auf dem Gebiet des DNA-Sequenzierens, also beim LESEN von DNA, haben nicht nur dazu geführt, dass die Kosten entsprechender Verfahren von ein paar Milliarden US-Dollar auf ein paar 1000 US-Dollar gesunken sind, sie haben vor allem dazu geführt, dass Daten, die in DNA gespeichert werden, fehlerfrei und schnell wieder ausgelesen werden können. Verbesserungen, wie die oben beschriebene, bei der DNA Synthese, die Polymerase Kettenreaktion durch Phosphoramidit-Synthese ersetzt haben, haben zur Folge, dass es mittlerweile recht einfach ist, Daten in DNA zu speichern.
Mit anderen Worten, es gibt eine Technologie, die DNA synthetisch herstellen kann, die Daten in die synthetisch hergestellte DNA schreiben kann, diese Daten zielgenau auslesen kann und fehlerfrei wiederherstellen kann, damit sie gelesen werden können. Die Auslese erfolgt derzeit noch mit Polymerase-Kettenreaktion, mit der die Daten der Zielregion der DNA ausgelesen, vervielfältigt, sequenziert und dekodiert werden, um dann, nach Beseitigung von Fehlern gelesen werden zu können. Mit diesem Verfahren ist es Microsoft und Twist Bioscience gelungen, mehr als 1 Gigabyte an Daten nicht nur in DNA zu speichern, sondern auch fehlerfrei wieder auszulesen [...Weiterlesen bei ScienceFiles]
DNA als Datenspeicher
Fluoreszierende DNA-Stränge werden genutzt, um digitale Nachrichten zu kodieren. Jedes Mal, wenn wir eine E‑Mail senden, einen Tweet absetzen oder etwas anderes online tun, generieren wir Daten – und weil wir viel online tun, generieren wir auch eine Menge Daten: etwa 2,5 Quintillionen Bytes pro Tag. Die meisten dieser Daten werden auf Servern in Rechenzentren gespeichert, die kostspielig und energieintensiv sind und viel Platz beanspruchen.
DNA ist eine vielversprechende Speicheralternative zu Rechenzentren, und jetzt haben Forscher der Boise State University eine neue Methode zur DNA-Datenspeicherung entwickelt, die eine große Hürde für ihre Einführung beseitigt – und sie sieht ein bisschen aus wie das Lite-Brite-Spielzeug, mit dem Sie vielleicht als Kind gespielt haben.
DNA-Datenspeicherung
Digitale Daten werden mit Sequenzen von nur zwei Zahlen gespeichert: 1 und 0. Die DNA verwendet Buchstaben (A, G, T und C), die chemische Basen darstellen, um Informationen zu speichern. Übersetzen Sie die digitalen Sequenzen von Daten in Codes mit vier Buchstaben, und Sie können DNA zum Speichern Ihrer digitalen Informationen verwenden.
Forscher schätzen, dass alle digitalen Daten der Welt in nur 20 Gramm DNA gepackt werden könnten, was bedeutet, dass wir tonnenweise Platz einsparen könnten, der derzeit von Datenzentren belegt wird. DNA ist auch viel haltbarer als Server und könnte unsere Informationen möglicherweise für Jahrtausende schützen, aber das Abrufen von Daten aus der DNA ist nicht einfach.
Um die gespeicherten Informationen zu entschlüsseln, ist eine große Maschine, ein sogenannter Sequenzer, erforderlich, und der Abrufprozess ist langsam – es kann fast einen Tag dauern, um ein einziges Wort zu entschlüsseln.
Eine geniale Idee
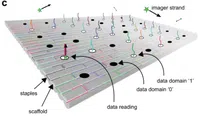
Um die Sequenzierung überflüssig zu machen, begannen die Forscher in Boise mit einsträngiger DNA (man stelle sich einen in zwei Hälften geteilten DNA-Strang vor). Sie programmierten diesen DNA-Strang so, dass er sich selbst zu einer flachen, rechteckigen Kartenform faltet. Dieses Rechteck hat 48 Stellen, an denen andere DNA-Einzelstränge angedockt werden können – Sie können sich diese Andockstellen wie die Löcher in einer Lite-Brite-Steckplatte vorstellen.
Jede Stelle auf dem DNA-Rechteck diente als ein „Bit“ im digitalen Code. Wenn ein DNA-Strang eingesteckt war, bedeutete das eine 1. Keine DNA in einem Loch bedeutet eine 0. Nachdem eine Nachricht über das Pegboard kodiert wurde, ist der nächste Schritt, sie abzurufen. Dazu werden fluoreszierende DNA-Stränge mit den Strängen auf der Stecktafel gepaart.
Nachdem die DNA-Stränge wie Stifte in einem Lite-Brite-Spielzeug aufgeleuchtet waren, konnten die Forscher sie mit einem höchstauflösenden Elektronenmikroskop abbilden. Ein Algorithmus konnte dann das Bild analysieren und das Muster aus 1en und 0en entschlüsseln, um die eingebettete Nachricht mit 100-prozentiger Genauigkeit abzurufen – eine DNA-Sequenzierung war nicht erforderlich.
Blick in die Zukunft
Die Wahrscheinlichkeit, dass Sie ein höchstauflösenden Elektronenmikroskop zu Hause haben, ist ungefähr so groß wie die eines DNA-Sequenzers, also wird dies noch nicht die Technologie sein, die die DNA-Datenspeicherung in den Mainstream bringt.
Dennoch ist es ein neuartiger, hochpräziser Ansatz, der nach Ansicht der Forscher eine weitere Entwicklung rechtfertigt. Die Forscher suchen nun nach Möglichkeiten, den Prozess der Kodierung und des Abrufs der Daten zu beschleunigen und die Datenmenge, die sie mit ihrem System speichern können, zu erhöhen.
- Datenbasis: FreeThink.com
Quelle: Unser Mitteleuropa